|
Datenanalyse
(in der Marktforschung). Aufgabe der Datenanalyse ist es, die erhobenen Daten zu prüfen, zu ordnen, zu erforschen und auf ein für die Entscheidungsfindung notwendiges und überschaubares Mass zu verdichten. Es können hierzu zahlreiche statistische Verfahren eingesetzt werden, die in Abhängigkeit von der Anzahl der berücksichtigten Variablen in uni-, bi- und multivariate Methoden eingeteilt werden (Statistik). Zur Datenanalyse stehen leistungsstarke Computerprogramme wie SPSS oder SAS zur Verfügung. Der Anwender muss sich jedoch stets über die Beschaffenheit des zugrunde liegenden Datenmaterials im Klaren sein, ob ein bestimmtes Verfahren auf bestimmte Daten anwendbar ist, das Programm vermag diesbezügliche Fehler bzw. Verletzungen der Anwendungsvoraussetzungen i.d.R. nicht zu erkennen (Messniveau, Gütekriterien, Codierung).
1. Univariate Datenanalyse: Analysiert wird eine einzige Variable. Dargestellt werden können Häufigkeitsverteilungen (absolute, relative, kumulierte relative Häufigkeiten). Typische Masszahlen sind Lokalisationsmasse (z.B. arithmetisches Mittel, Median, Modus) und Streuungsmasse (z.B. Varianz, Standardabweichung, Variationsbreite).
2. Bivariate Datenanalyse: Analysiert wird die Beziehung zweier Variablen. Von Interesse ist zunächst, ob überhaupt Zusammenhänge bestehen (z.B. identifizierbar per Kreuztabulierung bzw. x2-Unabhängigkeitstest). Darüber hinaus können die Art des Zusammenhangs (z.B. mittels Regressionsanalyse) sowie die Stärke des Zusammenhangs (z.B. mittels Korrelationsanalyse) ermittelt werden.
3. Multivariate Datenanalyse: Analysiert wird die Beziehung mindestens dreier Variablen. In diesem Kontext können strukturen-prüfende und strukturen-entdeckende Verfahren differenziert werden. Das Ziel der strukturen-prüfenden Verfahren liegt in der Überprüfung vermuteter Zusammenhänge zwischen Variablen. Der Anwender besitzt eine auf sachlogischen oder theoretischen Überlegungen basierende Vorstellung von den Kausalzusammenhängen zwischen Variablen und möchte diese mit Hilfe ausgewählter multivariater Verfahren überprüfen. Er muss also die von ihm betrachteten Merkmale in abhängige und unabhängige Variablen einteilen können (Beispiele: multiple Regressionsanalyse, Diskriminanzanalyse). Strukturen-entdeckende Verfahren dagegen sind multivariate Methoden, deren primäres Ziel im Auffinden von Zusammenhängen zwischen Variablen oder zwischen Objekten liegt. Hier besitzt der Anwender zu Beginn der Analyse noch keine Vorstellungen darüber, welche Beziehungszusammenhänge in einem Datensatz existieren (Beispiele: Faktorenanalyse, Clusteranalyse). Siehe auch Marktforschungsmethoden und Marktforschung, jeweils mit Literaturangaben.
Literatur: Backhaus, K., Erichson, B., Plinke, W., Weiber, R.: Multivariate Analysemethoden. Eine anwendungsorientierte Einführung, 10. Auflage, Berlin u.a. 2003; Berndt, R.: Marketing
1. Käuferverhalten, Marktforschung und Marketing-Prognosen, 3. Auflage, Berlin u.a. 1996; Sander, M.: Marketing-Management. Märkte, Marktinformationen und Marktbearbeitung, Stuttgart 2004. Internetadressen: www.gfk.de, www.gfk.at, www.ihagfk.ch (GfK-Gruppe); www.imshealth.com (Institute for Medical Statistics); www.infores.com (Information Resources); www.sas.com (SAS Institute); www.spss.com (Statistical Package for the Social Sciences); www.vnu.com (A.C. Nielsen).
Teilprozeß und -aufgabe der Marktforschung, bei dem die meist im Wege der Primärforschung erhobenen Daten formal und statistisch aufbereitet werden. Die formale Aufbereitung umfaßt zunächst die Rücklaufkontrolle, bei der die Urdaten- träger (Fragebogen, Beobachtungsprotokolle etc.) auf Vollständigkeit und Plausibilität, ggf. auch auf Fälschungen (Interviewereinfluß) hin überprüft werden. Nach Feststellung der Ausschöpfungs- bzw. Ausfallquote bei Stichprobenerhebungen muss ggf. über eine Nachbefragung entschieden werden. ZweiteTeilaufgabeistdie Verschlüsselungdtr Daten, die insb. der elektronischen Auswertung der Daten dient. Dabei wird den einzelnen AusprägungenallerVariableneinspezifi- scher Code zugewiesen. Das entsprechende Schema heißt Codeplan. Der Codeplan enthält auch Angaben darüber, an welcher Stelle der elektronisch gespeicherten Datensätze die jeweilige Variable zu finden ist, und welches Skalenniveau sie aufweist. Schwierigkeiten bereitet die Vercodung insb. bei offenen Fragen und qualitativen Merkmalen, wo man l. d.R. eine Klassifizierung inhaltlich ähnlicher Antworten vornehmen muß. Dabei kann durch unzweckmäßige Gruppenbildung ein systematischer Fehler auftreten. Fehlende Antworten müssen durch einen spezifischen Code (z. B. „9“) gekennzeichnet werden, damit bei der Auswertung eine Relativierung an der jeweils je nach Antwortausfällen unterschiedlichen Stichprobengesamtheit vorgenommen werden kann. Letzter Schritt der Datenaufbereitung ist die Erstellung einer Datenmatrix, i. d. R. durch Eingabe der auf sog. Codierungsblättern übersichtlich zusammengefaßten codierten Ergebnisdaten. Die Datenmatrix enthält in der einen Dimension - meist den Spalten - die einzelnen Merkmale (Variablen), in der anderen - meist den Zeilen - die „Fälle“ (Auskunftspersonen, Beobachtungsobjekte etc.). Die Fälle werden dabei durchnumeriert und können für entsprechende Auswertungen schon a priori ganz bestimmten Untergruppen zugewiesen werden. Bei computergestützten Befragungen entfallen ein Teil dieser Datenaufbereitungsaufgaben und die mit ihnen verbundenen Fehlerquellen. Trotzdem wird es auch dort notwendig sein, eine Plausibilitätskontrolle der Datenmatrix, z.B. im Hinblick auf die Einhaltung der Codespanne, durchzuführen, was in statistischen Programmpaketen (s.u.) auch maschinell durchgeführt werden kann. Die statistische Aufbereitung der Daten als zweiter Bereich der Datenanalyse läßt sich unter methodischen Gesichtspunkten in uni-, bi- und multivariate Analysen differenzieren. Univariate Verfahren begnügen sich mit der Analyse einer Variablen und deren Ausprägungen. Über alle Untersuchungsfälle hinweg ergibt sich dabei eine Häufigkeitsverteilung, die durch Berechnung von Mittelwerten und Streuungsmaßen komprimiert charakterisiert werden kann. Ziel der Datenanalyse ist hier also insb. eine Datenverdichtung.
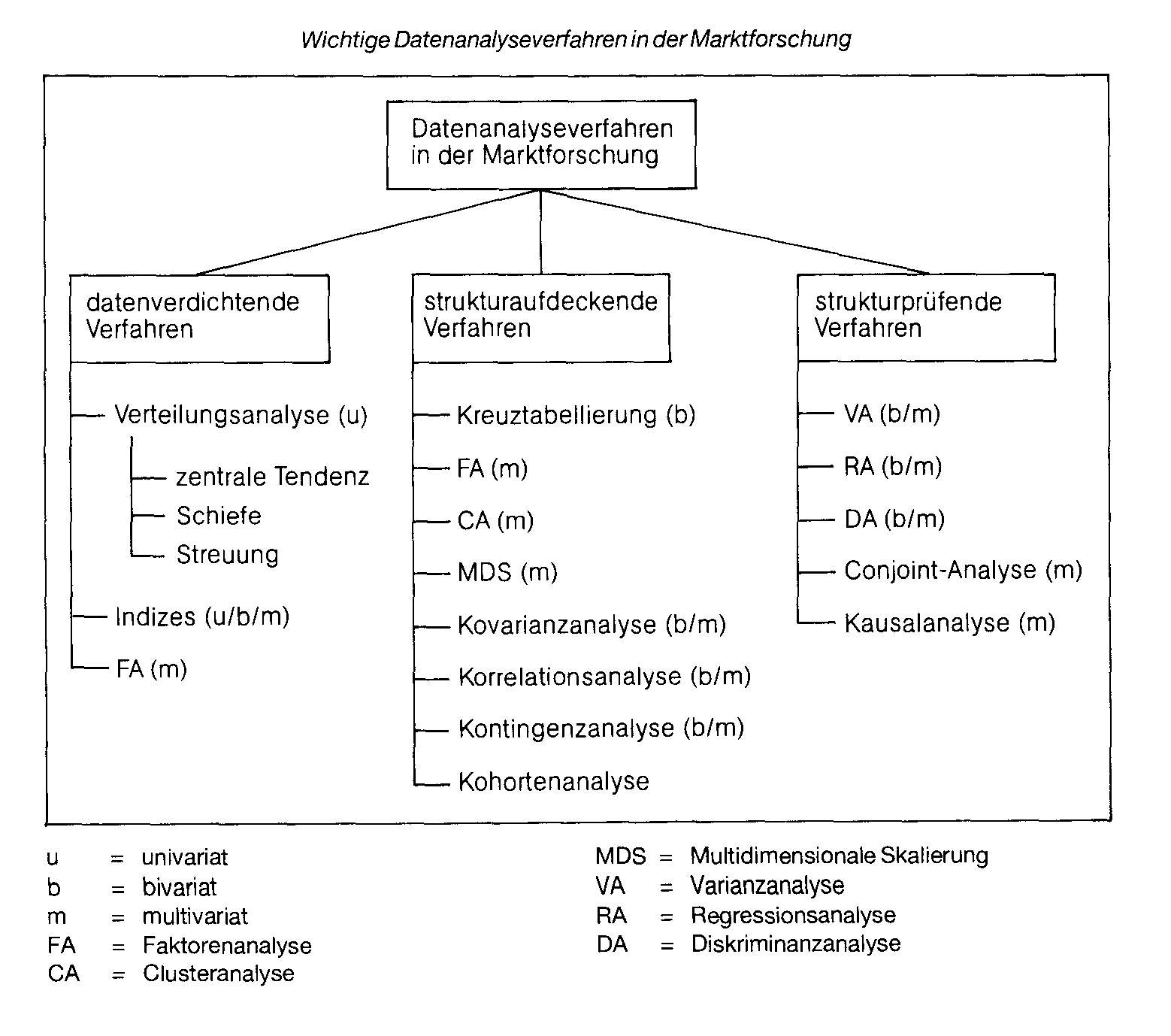 Bei den bivariaten Analysen wird dagegen durch Verknüpfung von zwei Merkmalen bereits der Versuch unternommen, Ähnlichkeiten zwischen Merkmalen und/oder Objekten sowie Zusammenhänge in Form von Korrelationen oder Abhängigkeiten zu entdecken (explorative Forschung) bzw. zu überprüfen (Inferenzstatistik). Als wichtigste Analysemethoden bieten sich hier die Kreuztabellierung, die Korrelationsanalyse sowie die (einfache) Regressionsanalyse an. Im Rahmen der Inferenzstatistik wird insb. auf die (einfache) Varianzanaly- se zurückgegriffen. Im Rahmen der Multivariatenanalyse werden in ähnlicher Untersuchungsabsicht wie bei der bivariaten Analyse drei oder mehr Variablen hinsichtlich ihrer inneren strukturellen Zusammenhänge analysiert. Dabei lassen sich Dependenz- und Interdependenzanalysen unterscheiden. Bei Depen- denzanalysen wird der Einfluß einer unabhängigen (erklärenden) Variablen auf eine abhängige (zu erklärende) Variable untersucht. Bei der Interdependenzanalyse geht es um wechselseitige Einflüsse bis hin zur Überprüfung komplexer Strukturmodelle im Rahmen der Kausalanalyse. Da die Herauslösung lediglich einer oder einiger weniger Variablen in uni- bzw. bivariaten Analysen aufgrund der Nichtberücksichtigung essentieller Zusammenhänge leicht zu Fehlschlüssen führen kann, besitzt die Multivariatenanalyse in der Marktforschung einen besonders hohen Stellenwert. Multivariate Analyseverfahren dienen aber auch der Datenverdichtung, etwa bei der Faktorenanalyse oder bei der Mehrdimensionalen Skalierung. Alle Analyseverfahren setzen ein bestimmtes Skalenniveau der Variablen voraus, das deshalb vorab genau überprüft und am besten auch im Codeplan vermerkt werden sollte. Besonders die multivariaten Analyseverfahren erfordern darüber hinaus die Einhaltung bestimmter Verteilungsannahmen, meist die sog. Multinormalverteilung, so dass vor Anwendung der Verfahren zunächst Anpassungstests durchzuführen sind. Die Abbildung gibt einen zusammenfassenden Überblick über die wichtigsten in der Marktforschung angewandten Methoden, gegliedert nach dem vordringlichen Untersuchungszweck. Dabei wird deutlich, dass einzelne Verfahren durchaus unterschiedlichen Zielen dienen können. Weiterhin wird sichtbar, dass eine Reihe von Methoden sowohl in bivariater als auch in multivariater Form durchgeführt werden können. Die statistische Komplexität vieler Auswertungsverfahrenführt inderPraxis nicht selten zum unzulässigen oder gar unsinnigen Einsatz bestimmter Analyseverfahren. Dies gilt insb. bei Anwendung bestimmter statistischer Programmpakete, z. B. SPSS, NCSS o. ä., in denen dem Anwender ein schier unerschöpfliches Potential an Auswertungsmöglichkeiten angeboten wird, was leicht zu „Da- tenhuberei“, d.h. zu theorielosem Auswerten von Datenmatrizen führt. Seriöse Auswertungen basieren stattdessen auf einem im vorhinein zumindest grob festgelegten Auswertungsplan, der von den Untersuchungszielen geleitet ist. Insb. bei der Analyse von Dependenzen sind dabei substanzwissenschaftlich gestützte Hypothesen erforderlich, die den Datenauswertungsprozeß steuern können (Hypothesenprüfung). Eine besondere Schwierigkeit der Datenanalyse im Marketing liegt darin, dass viele Daten kein metrisches Skalenniveau aufweisen, sondern qualitativer Natur sind (z.B. Käufer/Nichtkäufer, Käufer Marke A/Marke B etc., Anzeige A/B/C etc.). Während in der Inferenzstatistik mit den nichtparametrischen Testverfahren für derartige Fälle bereits seit langem eine Fülle spezifischer Statistiken zur Verfügung stehen, ist das Arsenal deskriptiver (inkl. erklärender) Analyseverfahren für nichtmetrische Variablen bisher eher beschränkt (Kontingenzanalyse). Ein v.a. in der wissenschaftlichen Marketingforschung nicht selten beschrittener Ausweg besteht hier darin, Objekte mittels Distanzindizes z.B. hinsichtlich ihrer Ähnlichkeit zu verknüpfen und im Wege der Mehrdimensionalen Skalierung auf einer metrischen Skala abzubilden. Die MDS weist einen weiteren Vorzug auf, der in der durch komplexe statistische Verfahren geprägten Auswertungsphase von nicht zu unterschätzender Bedeutung ist: Sie visualisiert Datenzusammenhänge, was nicht nur in der Phase der Datenpräsentation, sondern schon während der Auswertungsarbeiten zur Entdeckung bzw. Überprüfung von interessanten Zusammenhängen von großem Vorteil ist. Für diese wie für andere komplexe Analysen sind zwischenzeitlich Standard-Datenanaly- se-Programmpakete nahezu unersetzlich geworden. Es handelt sich dabei um Programmsysteme, die neben Routinen zur Einund Ausgabe sowie zur formalen Bearbeitung der Daten Programme zu nahezu allen statistischen Analysemethoden enthalten. Der Benutzer wird dabei durch eine mehr oder minder bequeme Oberfläche des Systems mit nur wenigen individuell auszugestaltenden Programmbefehlen bzw. -Optionen konfrontiert. Zu den bekanntesten Programmpaketen dieser Art zählen SPSS (Statistical Package for the Social Sciences), BMDP (früher BMD - „Biomedical Computer Programs) sowie S AS („Statistisches Analyse-System). Darüber hinaus existieren spezifische Programme für einzelne Analyseverfahren (z.B. für Clusteranalysen). Trends bei der Entwicklung von Daten- analysesystemen stellen die Integration von Graphik-Programmen, sog. Reportgeneratoren (Ausdruck unmittelbar druckfähiger Tabellen) sowie die Verfügbarkeit auf PCs dar (PC-Einsatz im Marketing). Einen einführenden Überblick über die gängigen Programmpakete geben Küffner/"Wittenberg. Bei den bivariaten Analysen wird dagegen durch Verknüpfung von zwei Merkmalen bereits der Versuch unternommen, Ähnlichkeiten zwischen Merkmalen und/oder Objekten sowie Zusammenhänge in Form von Korrelationen oder Abhängigkeiten zu entdecken (explorative Forschung) bzw. zu überprüfen (Inferenzstatistik). Als wichtigste Analysemethoden bieten sich hier die Kreuztabellierung, die Korrelationsanalyse sowie die (einfache) Regressionsanalyse an. Im Rahmen der Inferenzstatistik wird insb. auf die (einfache) Varianzanaly- se zurückgegriffen. Im Rahmen der Multivariatenanalyse werden in ähnlicher Untersuchungsabsicht wie bei der bivariaten Analyse drei oder mehr Variablen hinsichtlich ihrer inneren strukturellen Zusammenhänge analysiert. Dabei lassen sich Dependenz- und Interdependenzanalysen unterscheiden. Bei Depen- denzanalysen wird der Einfluß einer unabhängigen (erklärenden) Variablen auf eine abhängige (zu erklärende) Variable untersucht. Bei der Interdependenzanalyse geht es um wechselseitige Einflüsse bis hin zur Überprüfung komplexer Strukturmodelle im Rahmen der Kausalanalyse. Da die Herauslösung lediglich einer oder einiger weniger Variablen in uni- bzw. bivariaten Analysen aufgrund der Nichtberücksichtigung essentieller Zusammenhänge leicht zu Fehlschlüssen führen kann, besitzt die Multivariatenanalyse in der Marktforschung einen besonders hohen Stellenwert. Multivariate Analyseverfahren dienen aber auch der Datenverdichtung, etwa bei der Faktorenanalyse oder bei der Mehrdimensionalen Skalierung. Alle Analyseverfahren setzen ein bestimmtes Skalenniveau der Variablen voraus, das deshalb vorab genau überprüft und am besten auch im Codeplan vermerkt werden sollte. Besonders die multivariaten Analyseverfahren erfordern darüber hinaus die Einhaltung bestimmter Verteilungsannahmen, meist die sog. Multinormalverteilung, so dass vor Anwendung der Verfahren zunächst Anpassungstests durchzuführen sind. Die Abbildung gibt einen zusammenfassenden Überblick über die wichtigsten in der Marktforschung angewandten Methoden, gegliedert nach dem vordringlichen Untersuchungszweck. Dabei wird deutlich, dass einzelne Verfahren durchaus unterschiedlichen Zielen dienen können. Weiterhin wird sichtbar, dass eine Reihe von Methoden sowohl in bivariater als auch in multivariater Form durchgeführt werden können. Die statistische Komplexität vieler Auswertungsverfahrenführt inderPraxis nicht selten zum unzulässigen oder gar unsinnigen Einsatz bestimmter Analyseverfahren. Dies gilt insb. bei Anwendung bestimmter statistischer Programmpakete, z. B. SPSS, NCSS o. ä., in denen dem Anwender ein schier unerschöpfliches Potential an Auswertungsmöglichkeiten angeboten wird, was leicht zu „Da- tenhuberei“, d.h. zu theorielosem Auswerten von Datenmatrizen führt. Seriöse Auswertungen basieren stattdessen auf einem im vorhinein zumindest grob festgelegten Auswertungsplan, der von den Untersuchungszielen geleitet ist. Insb. bei der Analyse von Dependenzen sind dabei substanzwissenschaftlich gestützte Hypothesen erforderlich, die den Datenauswertungsprozeß steuern können (Hypothesenprüfung). Eine besondere Schwierigkeit der Datenanalyse im Marketing liegt darin, dass viele Daten kein metrisches Skalenniveau aufweisen, sondern qualitativer Natur sind (z.B. Käufer/Nichtkäufer, Käufer Marke A/Marke B etc., Anzeige A/B/C etc.). Während in der Inferenzstatistik mit den nichtparametrischen Testverfahren für derartige Fälle bereits seit langem eine Fülle spezifischer Statistiken zur Verfügung stehen, ist das Arsenal deskriptiver (inkl. erklärender) Analyseverfahren für nichtmetrische Variablen bisher eher beschränkt (Kontingenzanalyse). Ein v.a. in der wissenschaftlichen Marketingforschung nicht selten beschrittener Ausweg besteht hier darin, Objekte mittels Distanzindizes z.B. hinsichtlich ihrer Ähnlichkeit zu verknüpfen und im Wege der Mehrdimensionalen Skalierung auf einer metrischen Skala abzubilden. Die MDS weist einen weiteren Vorzug auf, der in der durch komplexe statistische Verfahren geprägten Auswertungsphase von nicht zu unterschätzender Bedeutung ist: Sie visualisiert Datenzusammenhänge, was nicht nur in der Phase der Datenpräsentation, sondern schon während der Auswertungsarbeiten zur Entdeckung bzw. Überprüfung von interessanten Zusammenhängen von großem Vorteil ist. Für diese wie für andere komplexe Analysen sind zwischenzeitlich Standard-Datenanaly- se-Programmpakete nahezu unersetzlich geworden. Es handelt sich dabei um Programmsysteme, die neben Routinen zur Einund Ausgabe sowie zur formalen Bearbeitung der Daten Programme zu nahezu allen statistischen Analysemethoden enthalten. Der Benutzer wird dabei durch eine mehr oder minder bequeme Oberfläche des Systems mit nur wenigen individuell auszugestaltenden Programmbefehlen bzw. -Optionen konfrontiert. Zu den bekanntesten Programmpaketen dieser Art zählen SPSS (Statistical Package for the Social Sciences), BMDP (früher BMD - „Biomedical Computer Programs) sowie S AS („Statistisches Analyse-System). Darüber hinaus existieren spezifische Programme für einzelne Analyseverfahren (z.B. für Clusteranalysen). Trends bei der Entwicklung von Daten- analysesystemen stellen die Integration von Graphik-Programmen, sog. Reportgeneratoren (Ausdruck unmittelbar druckfähiger Tabellen) sowie die Verfügbarkeit auf PCs dar (PC-Einsatz im Marketing). Einen einführenden Überblick über die gängigen Programmpakete geben Küffner/"Wittenberg.
Literatur: Hüttner, M., Grundzüge der Marktforschung, 4. Aufl., Berlin 1989. Knz,J., Methodenkritik empirischer Sozialforschung, Stuttgart 1981. Küffner, H.; Wittenberg, R., Datenanalyse- systeme für statistische Auswertungen, Stuttgart 1985.
|
