|
Datenbanken
Inhaltsübersicht
I. Betriebswirtschaftliche Anwendungen
II. Datenorganisation
III. Datenbanksysteme für analytische Anwendungen
IV. Das Zusammenspiel
V. Weitere Aspekte von Datenbanksystemen und Ausblick
I. Betriebswirtschaftliche Anwendungen
Unter dem Gesichtspunkt von Datenverarbeitungs(DV)-Unterstützung ist es zweckmäßig, die betriebswirtschaftlichen Aufgabenstellungen in solche aufzuteilen, welche die Abwicklung der Prozesse zum Gegenstand haben, und solche, die die Steuerung der Prozesse betreffen. Bei den abzuwickelnden Aufgaben kann zwischen kundenbezogenen Prozessen (Kundenmanagement, Auftragsabwicklung, ?) und Prozessen, die sich auf die Infrastruktur des Unternehmens beziehen (Finanzierung, Anlagenmanagement, Personalmanagement, ?), unterschieden werden. Die Aufgaben zur Steuerung der Prozesse umfassen die Planung und Vorgabe, die Koordination, das Messen und Bewerten sowie die Analyse (siehe Abb. 1).
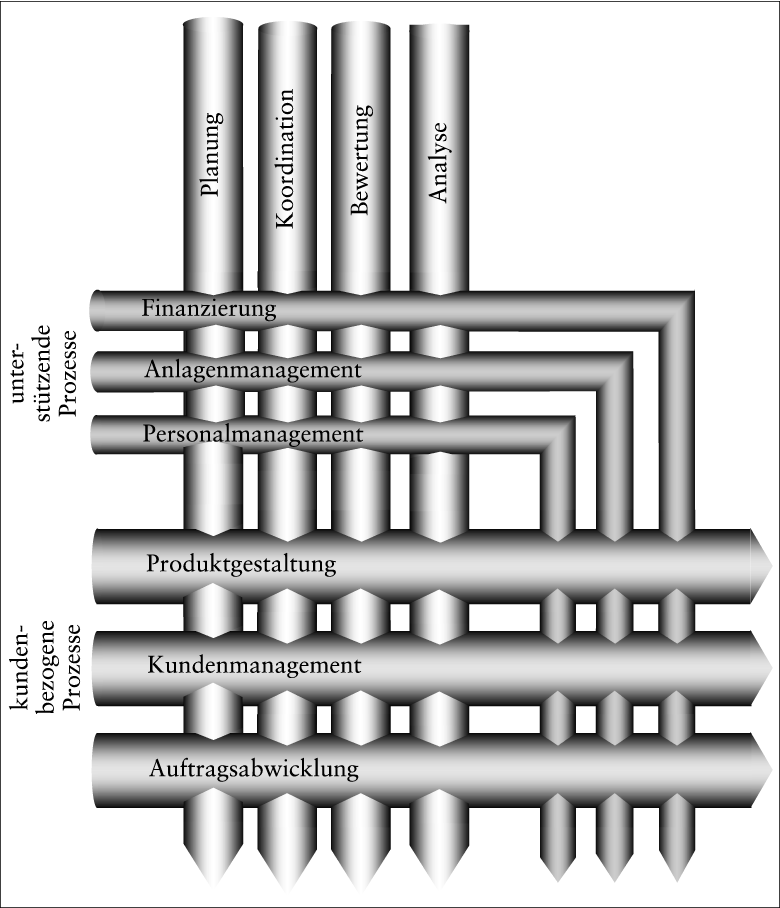
Abb. 1: Prozesssicht auf die betriebswirtschaftlichen Aufgabenstellungen
Die Funktionen des Finanz- und Rechnungswesens berühren alle Bereiche: Die korrekte Abwicklung der Zahlungen ist teilweise ein spezieller Schritt in einem umfassenderen Prozess (z.B. Zahlungen, die mit Kundenaufträgen, Material- und Anlagenbeschaffungen verbunden sind); teilweise handelt es sich um eigenständige Prozesse (z.B. Finanzierungen). Die Bewertungsfunktion ist ebenfalls mit den Prozessen verbunden; sie kann als Vorbereitung für die steuernden Aufgaben gesehen werden. Controlling ist ein Synonym für Steuerung; es darf dabei aber nicht nur als Steuerung mit kostenrechnerischen Ansätzen verstanden werden. Vielmehr müssen auch die Größen zur externen Rechnungslegung und die nicht-monetären Steuerungsgrößen einbezogen werden.
Die Trennung zwischen Prozess-Abwicklung und Prozess-Steuerung findet sich auch im Schmalenbach\'schen Ansatz einer Grundrechnung mit darauf aufbauenden Sonderrechnungen (Auswertungsrechnungen) wieder (vgl. Schmalenbach, E. 1948). Die Grundrechnung trennt datenmäßig die abwickelnden Systeme von den steuernden Systemen.
II. Datenorganisation
Bzgl. der Datenorganisation können zwei Konzeptionen unterschieden werden. Bei der programmorientierten Datenverwaltung sind die Daten fest mit den sie verarbeitenden Programmen verbunden. Die Datenstruktur und die Inhalte werden „ Datei “ genannt. Bei der datenorientierten Datenverwaltung werden die Daten losgelöst von den Programmen, die sie verarbeiten, verwaltet. Die Datenstruktur und die Inhalte werden „ Datenbank “ genannt; die Funktionen zur Bearbeitung der Datenbank sind im Datenbank(management)system zusammengefasst.
Speziell für große betriebliche Anwendungen ist die datenorientierte Datenverwaltung der programmorientierten aus folgenden Gründen überlegen:
| - | Verringerung der Redundanz: Ein identischer Sachverhalt wird nur ein einziges Mal abgespeichert. Dies reduziert nicht nur den Speicherbedarf, sondern garantiert auch eine Konsistenz im Falle von Einfügen, Ändern und Löschen. | | - | Erhöhung der Datenunabhängigkeit: Die Isolierung der Anwendungsprogramme von der Datenverwaltung wird „ Datenunabhängigkeit “ genannt. Dabei werden verschiedene Grade unterschieden: physische Datenunabhängigkeit (das Anwendungsprogramm ist unabhängig davon, wie die Daten physisch auf den Speichermedien abgelegt sind), Zugriffspfadunabhängigkeit (das Anwendungsprogramm ist unabhängig davon, wie die Daten manipuliert, d.h. gelesen, eingefügt, geändert und gelöscht werden), Datenstrukturunabhängigkeit (das Anwendungsprogramm ist unabhängig davon, durch welche logischen Strukturen die reale Welt abgebildet wird). Je höher der Grad an Datenunabhängigkeit ist, desto höher wird die Benutzereffizienz. Die physische Datenunabhängigkeit und die Zugriffspfadunabhängigkeit erhöhen die Effizienz der Anwendungsentwickler, die Datenstrukturunabhängigkeit erhöht die Effizienz der interaktiven Problemlöser. | | - | Zentrale Dienste: Datenbanksysteme übernehmen zahlreiche Aufgaben, die dadurch, dass sie zentral erfolgen, allen Anwendungen zur Verfügung stehen: Datendefinition, Datenzugriff (Optimierung, Integrität, Konsistenz, Schutz), Datensicherheit, Verfügbarkeit, ? . |
Zur Implementierung von Datenbanksystemen wurde von der ANSI/SPARC-Gruppe der in Abb. 2 dargestellte Vorschlag gemacht (vgl. ANSI, /SPARC, 1975).
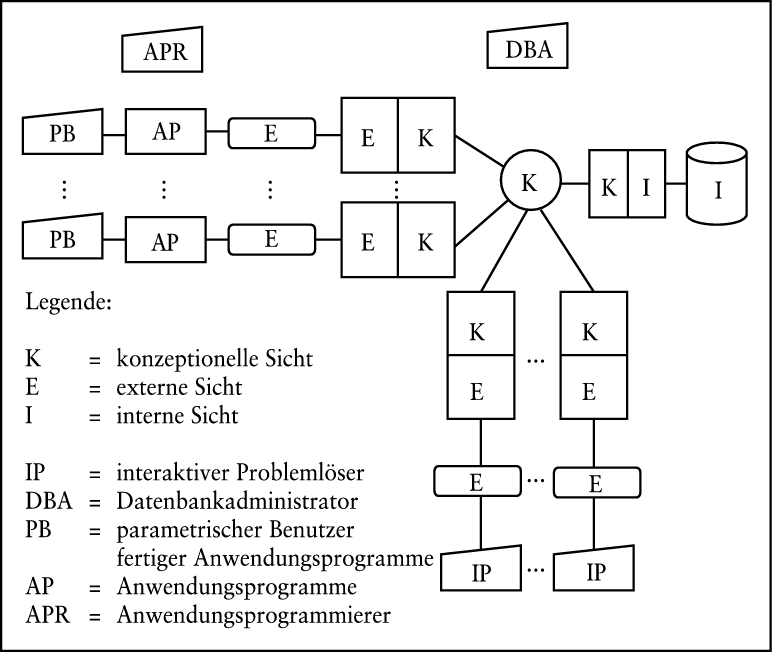
Abb. 2: Architektur eines Datenbanksystems nach ANSI/SPARC
Die Datenstruktur und die Funktionen, mit denen sie beschrieben wird, liegen im konzeptionellen Schema. Die Beschreibung und Implementierung der logischen und der physischen Zugriffspfade liegen im internen Schema. Endbenutzer arbeiten nicht direkt mit dem konzeptionellen Schema, sondern jeweils mit einem Ausschnitt. Dieses so genannte externe Schema enthält die jeweilige Definition sowie die Funktionen zu ihrer Implementierung
Den Elementen dieser Architektur können verschiedene Benutzergruppen zugeordnet werden. Der Datenbankadministrator entwirft das aus den externen Schemata resultierende konzeptionelle Schema und implementiert dies im internen Schema. Interaktive Problemlöser formulieren die aus ihrer betrieblichen Aufgabenstellung resultierenden Anfragen. Sie können den unterschiedlichen Graden an Datenunabhängigkeit folgend in weitere Gruppen aufgeteilt werden: Analysts und Researcher (kennen das Datenbankschema und die Datenmanipulationssprache), gelegentliche Benutzer (kennen nur die Begriffe ihres Anwendungsgebietes und die Grammatik zu deren Verbindung). Sie benutzen unmittelbar das externe Schema. Anwendungsprogrammierer implementieren komplexe Aufgabenstellungen in so genannten Anwendungsprogrammen; auch sie benutzen unmittelbar das externe Schema. Parametrische Benutzer lösen die aus ihrer betrieblichen Aufgabenstellung resultierenden Aufgaben, indem sie diese Anwendungsprogramme parametrisieren.
Bei Datenbanksystemen wird zwischen solchen unterschieden, die Daten für die Abwicklung von Geschäftsprozessen verwalten (Datenbanksysteme für transaktionale Anwendungen s. Kapitel III), und solchen, die Daten für die Steuerung (synonym: Entscheidungsunterstützung, Decision Support) des Unternehmens verwalten (Datenbanksysteme für analytische Anwendungen s. Kapitel IV). Daneben stehen Datenbanksysteme zur Verwaltung von nicht-formatierten Daten (s. Kapitel VI).
Die Aufteilung der Datenbanksysteme in diese drei Kategorien ist mit den unterschiedlichen Charakteristiken der Anwendungen, den unterschiedlichen Charakteristiken der daraus resultierenden Datenbestände und den unterschiedlichen Charakteristiken der daraus wiederum resultierenden Implementierungen begründet. Es ist offensichtlich, dass nicht-formatierte Daten (Texte, Bilder, ?) nach anderen Konzepten verwaltet werden müssen als formatierte Daten (Begriffsausprägungen, Zahlen). In der folgenden Tabelle wird dargestellt, warum Datenbestände für die Abwicklung von Geschäftsvorfällen (OLTP: Online Transaction Processing) anders zu verwalten sind als Datenbestände für die Steuerung (OLAP: Online Analytical Processing).
III. Datenbanksysteme für transaktionale Anwendungen
Man unterscheidet drei Konzeptionen, nach denen das Datenmodell – also die logische Verknüpfung zwischen den Daten – beschrieben wird: Hierarchie, Netzwerk, Relation (vgl. Date, C.J. 1979). Entsprechend diesen so genannten Datenmodellkonzeptionen werden auch die Datenbanksysteme eingeteilt: Hierarchische Datenbanksysteme, netzwerkorientierte Datenbanksysteme, relationale Datenbanksysteme. Relationale Datenbanksysteme weisen im Vergleich zu hierarchischen und netzwerkbasierten einen höheren Grad an Datenunabhängigkeit auf und haben sich deshalb am Markt durchgesetzt.
Relationale Datenbanksysteme (vgl. Codd, E.F. 1970) benötigen zur Beschreibung von Datenstrukturen nur die beiden Begriffe „ Relation “ und „ Schlüssel “ . Als Relation wird in der Mathematik eine Untermenge des Cartesischen Produktes zwischen n Mengen bezeichnet. Die Ausprägungen des Cartesischen Produktes bzw. der Relation heißen Tupel.Beispiel: Die Menge der Lieferanten und die Menge der Materialien eines Unternehmens spannen ein zweidimensionales Cartesisches Produkt auf; auf diesem ist eine Relation „ Lieferbeziehung “ definiert. In dieser ist ein Tupel „ Lieferant A “ und „ Material 1 “ enthalten. Eine Menge M1 kann in mehreren Relationen vorkommen. Beispiel: Die Menge „ Material “ kommt in den Relationen Materialstamm, Stückliste, Arbeitsplan, Kundenauftrag, Bestellung usw. vor. Eine Menge M1 kann in einer einzigen Relation mehrfach vorkommen; sie nimmt dann unterschiedliche Rollen ein. Beispiel: Die Menge „ Material “ kommt in der Relation „ Stückliste “ in der Rolle „ Oberteil “ und „ Unterteil “ vor. Eine Menge M1 wird Domäne genannt, wenn sich die Aussage auf das gesamte Datenbankschema bezieht; sie wird Attribut genannt, wenn sich die Aussage auf eine bestimmte Relation bezieht. Beispiele für Aussagen: Die Domäne „ Material “ hat ein bestimmtes Format; das Attribut „ Material “ steht in der Relation „ Arbeitsplan “ an dritter Stelle. Von den Tupeln einer Relation wird Eindeutigkeit verlangt. Wenn alle Tupel einer Relation unterschiedlich sind, so existiert mindestens ein Attribut oder eine Gruppe von Attributen mit identifizierender Eigenschaft. Dieses Attribut oder diese Attributgruppe heißt Schlüssel.
Während bei der programmorientierten Datenverwaltung die Aufgabe, einen komplexen Realitätsausschnitt in die logische Darstellungsebene zu überführen, mit der Entwicklung einer spezifischen Anwendung verbunden ist, ist dies bei der datenorientierten Datenverwaltung eine eigenständige Aufgabe. Hierbei wird der Realitätsausschnitt unabhängig von den Anwendungen modelliert. Die Herausforderung besteht darin, ein Datenmodell zu entwerfen, auf das möglichst viele, im Entwurfszeitpunkt z.T. noch unbekannte Anwendungen zugreifen können.
Der Entwurf eines Datenmodells kann nach folgenden Methoden erfolgen:
| - | Formale Ansätze: Hierbei wird von einer – z.B. aufgrund rudimentärer Betrachtungen der Realität (Formulare, existierende Anwendungen) – gegebenen Datenstruktur ausgegangen. Als eigentliche Abstraktion wird die sich hieran anschließende Optimierung des logischen Aufbaus angesehen. Diese orientiert sich meist an einer Reduzierung der Datenredundanz und der Zahl der Zugriffe beim Änderungsdienst. Zu diesen formalen Ansätzen gehört beispielsweise die von Codd (vgl. Codd, E.F. 1971) entwickelte Normalformenlehre. | | - | Begriffsorientierte Ansätze: Hierbei werden alle in einem Realitätsausschnitt vorkommenden Begriffe zueinander in Beziehung gesetzt. Zu den begriffsorientierten Ansätzen gehören das von Chen entwickelte Entity Relationship Modell (vgl. Chen, P.P. 1976; Chen, P.P. 1977) und die von Wedekind entwickelte Objekttypen-Methode (vgl. Wedekind, H. 1979). Beide erklären – ähnlich zur Vorgehensweise bei einem ingenieurmässigen Entwurf – mittels Konstruktionsoperationen den Zusammenhang zwischen Begriffen. Bei der Objekttypen-Methode werden die Begriffe als Objekttypen bezeichnet. Zur Erklärung des Begriffszusammenhangs bedient sie sich folgender Operationen:
Verallgemeinerung; die entgegengesetzte Operation heißt Spezifizierung: Bei der Verallgemeinerung wird ein Merkmal aus der Definition des Objekttyps eliminiert. Beispiel: im entscheidungsorientierten Rechnungswesen stehen die Begriffe „ Absatzgebiet “ , „ Kundengruppe “ und „ Produkt “ einerseits und Bezugsobjekt andererseits über die Verallgemeinerungsoperation miteinander in Beziehung.
Komposition; die entgegengesetzte Operation heißt Dekomposition: Komposition bedeutet eine Verschmelzung elementarer Objekttypen zu komplexen entsprechend den Anordnungs- und Wirkungsbeziehungen des Realitätsausschnittes. Beispiele: Der Begriff „ Auftrag “ wird in einem konkreten Realitätsausschnitt als eine Komposition aus „ Kunde “ und „ Bestellzeitpunkt “ benutzt; der Begriff „ Auftragsposition “ ist eine Komposition von „ Auftrag “ und „ Produkt “ . |
Der entscheidende Vorzug der Objekttypen-Methode gegenüber den formalen Ansätzen liegt in der entstehungsphänomenologischen Betrachtung der Begriffe. Es ist nicht notwendig, von einem strukturpräjudifizierenden Ad-hoc-Modell auszugehen. Der Ausgangspunkt der Datenmodellierung übt keinen Einfluss auf das Endergebnis aus, da in einem bestimmten Realitätsausschnitt alle verwendeten Begriffe in einem eindeutigen Verhältnis zueinander stehen, das durch die genannten Konstruktionsoperationen erklärt wird. Werden beim Objekttypen-Ansatz bestimmte Restriktionen eingehalten (keine Synonyme, keine Gattungsbegriffe als Attribute, keine unbegründbaren Begriffe), so entstehen Relationen in 3. Nomalform.
Welche Begriffe in ein zu implementierendes Datenmodell aufgenommen werden, hängt von den zu erwartenden Anwendungen ab. Bei den begriffsorientierten Ansätzen können alle Begriffe semantisch erklärt werden; es bietet sich deshalb an, alle diese Begriffe als Datenauskunftssystem zu implementieren. Ein so konzipiertes Datenauskunftssystem bildet die Brücke zwischen der Begriffswelt der Benutzer und dem Datenmodell.
IV. Datenbanksysteme für analytische Anwendungen
Aus den in Kapitel II beschriebenen Charakteristiken von analytischen Anwendungen und den daraus resultierenden Charakteristiken der Datenbestände folgt, dass die erforderlichen Daten replikativ zu den Daten der transaktionalen Anwendungen gehalten werden müssen.
Für diese Replikation gibt es noch einen zweiten, davon unabhängigen Grund. In der betrieblichen Realität ist im Allgemeinen von einer Vielzahl transaktionaler Systeme auszugehen. Diese Systeme unterstützen in der Regel einzelne Prozesse (z.B. Kundenauftragsabwicklung, Personalabrechnung, Maschinenverwaltung); häufig beziehen sie sich nur auf die Prozesse innerhalb einzelner Organisationseinheiten (z.B. einer Gesellschaft, eines Geschäftsbereichs oder einer Regionalorganisation). Die Systeme sind meist anwendungslogisch nicht miteinander verbunden und stehen unter der Steuerung nicht kompatibler Betriebs- und Datenbanksysteme. Diese Heterogenität zeigt sich auf der technischen Ebene (z.B. unterschiedliche Codepages), auf der Ebene der Datenbestände (z.B. Aufträge bereits im Auftragsabwicklungssystem fakturiert, aber in der Finanzbuchhaltung noch nicht gebucht) und auf der Ebene der Semantik (z.B. Definition des Begriffs „ Umsatz “ ). Für diese heterogene Systemlandschaft gibt es zahlreiche Gründe: gewollte Herstellervielfalt, Best-of-Breed-Ansatz, sukzessive Investitionsentscheidungen usw.
Für die steuernden Aufgaben in einem Unternehmen werden aber im Allgemeinen Informationen aus verschiedenen Bereichen (Prozesse, Funktionsbereiche, Organisationseinheiten, Unternehmensumwelt) benötigt. Es ist also eine Anwendungsumgebung zur Verfügung zu stellen, die die Daten der verschiedenen transaktionalen Anwendungssysteme technisch gemeinsam auswertbar macht, eine bzgl. Metadaten und Anwendungsdaten konsistente Datensicht ermöglicht und flexible Auswertungen erlaubt (vgl. Inmon, W.H. 1999; Inmon, W.H./Imhoff, C./Battas, G. 1996; Kimball, R. 1996). Die Lösung hierfür ist ebenfalls Replikation.
Aus diesen beiden Gründen (unterschiedliche Datenverwaltungskonzepte, heterogene Systemlandschaft) bauen analytische Anwendungen auf Datenbeständen auf, die getrennt von denen der transaktionalen Anwendungen gehalten werden. Diese Datenbestände werden „ Data Warehouse “ genannt; die Systeme zur Verwaltung dieser Datenbestände heißen „ Data-Warehouse-(Management)-Systeme “ . Ein Data Warehouse ist im Allgemeinen keine 1 : 1 Replikation der operationalen Datenbestände, sondern entsteht durch Transformation dieser in eine „ modellierte Welt “ .
Data-Warehouse-Systeme beinhalten Funktionen zum Management des Ladeprozesses, der Datenablage und der Auswertung der Daten (vgl. Oehler, K. 2000). Das Load Management enthält Funktionen zum Extrahieren, Transformieren und Laden der Daten. Das Data Management enthält Funktionen zur Verwaltung der Daten, der Benutzerzugriffe, der Datensicherung usw. Das Query Management enthält Funktionen zur Selektion der Daten, zur Berechnung von Kennzahlen, zur optischen Datenaufbereitung sowie zur Analyse (Drill-down, ?).
Zusätzlich zum Data Warehouse werden häufig noch zwei spezielle Datenablagen eingeführt. Das Operational Data Store dient dazu, die Daten einzelner Transaktionen in der Decision Support Anwendungsumgebung verfügbar zu machen. Es bildet also die Brücke vom Data Warehouse zum transaktionalen System. Bei Data Marts handelt es sich um Datenbestände, die für spezielle Fragestellungen zur Verfügung gestellt werden. Sie weisen eingeschränkte oder erweiterte Datenmodelle aus, die dem Anwender die benötigten Funktionen ermöglichen.
Details zum Konzept des Data Warehouse sind im Beitrag Data Warehouse zu finden.
V. Das Zusammenspiel
Abb. 3 zeigt das Zusammenspiel von transaktionalen Anwendungen, analytischen Anwendungen, ihren jeweiligen Datenbeständen und dem Data Warehouse. Transaktionale Anwendungen (z.B. Kundenauftragsabwicklung, Fertigungsaufträge) wickeln einzelne Geschäftsprozesse ab und legen die Ergebnisse in den entsprechenden Datenbanken ab. Bereits während der Abwicklung werden die Geschäftsprozesse – sofern erforderlich – für analytische Bearbeitungen vorbereitet (z.B. Bewertung, Kontenfindung). Die Daten werden periodisch in das Data Warehouse übertragen. Analytische Anwendungen dienen als der Unternehmens- und Geschäftssteuerung. Beispiele für solche Anwendungen sind das Vertriebscontrolling, Activity Based Management, Balanced Scorecard, das General Ledger, die Konsolidierung, die Planung und Budgetierung, Data Base Marketing, Risk Management, usw.
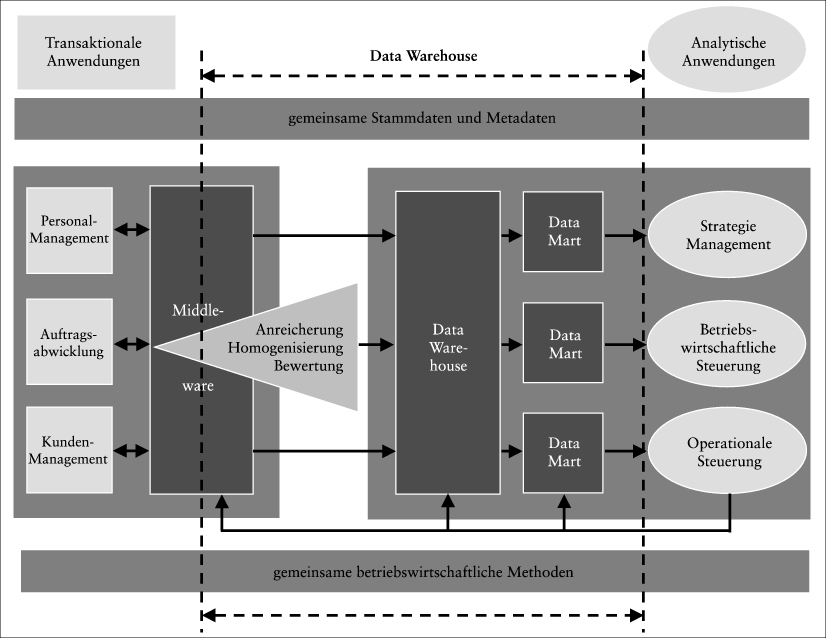
Abb. 3: Unternehmensweite Anwendungsarchitektur
Die analytischen Anwendungen agieren unmittelbar auf dem Data Warehouse. Hierdurch entsteht ein Zielkonflikt mit dem auf lesenden Zugriff optimierten Data Warehouse. Um diesen aufzulösen, besitzen analytische Anwendungen in der Regel eigene Data Marts.
Sollen die Ergebnisse der analytischen Anwendungen dem unternehmensweiten Data Warehouse bekannt sein, werden sie periodisch aus dem Data Mart in das Data Warehouse übertragen. Gelegentlich haben analytische Anwendungen auch Auswirkung auf die transaktionalen Systeme (z.B. neue Stammdaten, Budgetvorgaben, Verrechnungspreise, ?). Die Daten werden dann dorthin übertragen und kommen über diesen Weg in das unternehmensweite Data Warehouse zurück.
Gegenüber dem klassischen Data Warehouse-Ansatz ist einer analytischen Anwendung eine zusätzliche Komplexität immanent. Diese entsteht zum einen dadurch, dass Daten erzeugt werden, die in den Data Mart, bei unternehmensweiter Bedeutung auch im Data Warehouse und bei Verwendung in den Transaktionssystemen auch dort fortgeschrieben werden müssen. Zum anderen werden z.T. Funktionen benötigt, die auch im Data Warehouse und in den transaktionalen Systemen zum Einsatz kommen, z.B. Bewertungsmethoden, Aufteilungsmethoden. Gute Implementierungen von analytischen Anwendungen erlauben es daher, Metadaten, Stammdaten und Methoden gemeinsam mit dem Data Warehouse und den Transaktionssystemen zu nutzen.
Als Beispiel für eine analytische Anwendung sei die von Riebel entwickelte relative Einzelkosten- und Deckungsbeitragsrechnung zur entscheidungsorientierten Unternehmensführung näher ausgeführt (zum Konzept vgl. Riebel, R. 1994). Sie basiert auf einer Grundrechnung (s. Kapitel I), die als Teil des Data Warehouse oder als spezieller Data Mart bezeichnet werden kann. Die Grundrechnung wird aus den transaktionalen Systemen versorgt und enthält gegenüber der Datenbasis einer einfachen Kosten- und Leistungsrechnung zusätzliche Kosten- und Erlöskategorien sowie mehrdimensionale Bezugsobjekte. Die Verarbeitungsoperationen stellen teilweise einfache Datenbankabfragen dar. Teilweise handelt es sich auch um Planungen und Budgetzuordnungen, um modellbasierte Simulationen und um Optimierungen, deren Ergebnisse im Data Warehouse/Data Mart und gegebenenfalls in den transaktionalen Anwendungen abgespeichert werden (zur Implementierung vgl. Sinzig, W. 1990).
VI. Weitere Aspekte von Datenbanksystemen und Ausblick
Unter Business Intelligence werden diejenigen Funktionen von Data Warehouse-Systemen zusammengefasst, die für den Einsatz in Unternehmen – im Gegensatz zu Wissenschaft, Technik, Volkswirtschaft, Recht, usw. – wichtig sind und von den allgemeinen Konzepten abgedeckt werden müssen. Im Folgenden sind einige Beispiele aufgeführt:
| - | Zur Behandlung von Währungen müssen spezielle Funktionen zur Verfügung stehen: Währungsumrechnungen, Behandlung von Transaktions-, Haus- und Konzernwährung, Abspaltung von Währungseffekten. | | - | Hierarchische Beziehungen müssen modellierbar sein, um Binnenumsatzeleminierungen, Organisationsänderungen und Simulationen vornehmen zu können. | | - | Verbräuche, Bestände, Preise und Prozentsätze verhalten sich bei ihrer Aggregation unterschiedlich. | | - | Zeitabhängigkeiten und Versionierung müssen darstellbar sein. |
Business Intelligence stellt also eine Verfeinerung des datenbezogenen Ansatzes dar.
Bei den bisherigen Ausführungen wurde davon ausgegangen, dass in der Datenbank formatierte Daten verwaltet werden. Für das Management nicht-formatierter Daten, wie z.B. Dokumente, Zeichnungen, Bilder und Filme, existieren spezielle Implementierungen (Dokumenten-Datenbanken, Multimedia-Datenbanken, Objektorientierte Datenbanken) (vgl. Meyer-Wegener, K. 1991; Besser, H. 1995; Cox, J. 1996; Khoshofian, S./Baker, A.B. 1996). Auch für die anwendungsunabhängige Verwaltung von Methoden und Modellen wurden Management Systeme entwickelt.
Ein anderer Aspekt stellt auf den Ursprung der Daten ab. Hierbei wird zwischen unternehmensinternen und unternehmensexternen Daten unterschieden. Verwaltungssysteme für unternehmensexterne Daten stellen besondere Anforderungen an den Zugriffsschutz. Des Weiteren müssen die unternehmensexternen Daten mit den unternehmensinternen Daten gekoppelt werden, um sie gemeinsam auswerten zu können. Im Allgemeinen werden die unternehmensexternen Daten periodisch in die unternehmenseigenen Datenbanksysteme übertragen, um sie gemeinsam mit den unternehmensinternen Daten auswerten zu können. Ein anderer Ansatz besteht darin, im Zeitpunkt der Anfrage die unternehmensexternen Daten aus den unternehmensfremden Datenbanksystemen zu beschaffen.
Das Internet bietet die Möglichkeit so genannter kollaborativer Szenarien. Hierdurch kann die Datenredundanz über Unternehmensgrenzen hinweg verringert werden. Sowohl transaktionale als auch analytische Anwendungen greifen in einem solchen Szenario im Verarbeitungszeitpunkt auf die unternehmensexternen Daten zu. Unternehmensübergreifende Produktkataloge sind ein Beispiel hierfür. Auch die redundanzfreie Verwaltung konkreter Produkte wäre möglich. Vorstellbar ist auch, dass Bestellung und Kundenauftrag, die ja zum großen Teil redundante Daten enthalten, nur beim Verkäufer, beim Käufer oder bei einem Dritten verwaltet werden. Notwendige Voraussetzungen für solche Szenarien sind standardisierte Schnittstellen (etwa mittels XML (Extensible Markup Language) als Trägertechnologie), erweiterter Datenschutz und Datensicherheit sowie rechtliche Rahmenbedingungen für das datenverwaltende Unternehmen ähnlich denen einer Bank.
Aus Sicht der Hersteller von Datenbanksystemen ist ein Trend erkennbar, dass – konform zur Forderung hoher Datenunabhängigkeit, insbesondere hoher Zugriffspfadunabhängigkeit – die Konzeptionen zur Verwaltung von Daten zur transaktionalen Verarbeitung und zur Verarbeitung für Steuerungszwecke in einem einzigen System implementiert werden. In einem solchen System werden – für den Endanwender verborgen – je nach Art der Verarbeitung unterschiedliche Zugriffspfade beschritten, je nachdem, ob es sich um eine transaktionale Verarbeitung oder um eine analytische Anwendung handelt. In einem solchen System wären auch Konstrukte wie ODS und Data Marts für den Endanwender nicht mehr sichtbar.
Literatur:
ANSI/X3/SPARC, : Study Group on Data Base Management Systems: Interim Report, in: ACM SIGMOD, Bd. 7, H. 2, 1975, S. 72
Besser, Howard : Getting the picture on image databases: The basics, Weston 1995
Codd, E.F. : Further Normalization of the Data Base Relational Model, in: Database Systems, Courant Computer Science Symposia 6, hrsg. v. Rustin, R., Englewood Cliffs (N.J.) 1971, S. 33 – 64
Codd, E.F. : A relational model for large shared data banks, in: Communications of the ACM, Jg. 13, H. 6/1970, S. 377 – 387
Cox, John : Object databases driving new generation of applications, Framingham 1996
Chen, Peter Pin-San : The entity-relationship model – A basis for the enterprise view of data, in: AFIPS, Proceeding of the National Computer Conference, 1977, S. 77 – 84
Chen, Peter Pin-San : The Entity-Relationship Model – Toward a Unified View of Data, in: ACM Transactions on Database Systems, H. 1/1976, Bd. 1, S. 9 – 36
Date, Chris. J. : An Introduction to Database Systems, Reading (Mass.), 7. A., 1999
Inmon, William H. : Building the Data Warehouse, New York, 2. A., 1996
Inmon, William H./Imhoff, Claudia/Battas, Greg : Building the operational data store, New York, 2. A., 1999
Khoshofian, Stetrag/Baker, A. Brad : Multimedia and Imaging Databases, San Francisco, 1996
Kimball, Ralph : The Data Warehouse Toolkit, New York 1996
Mertens, Peter : Integrierte Informationsverarbeitung Bd. 1. Administrations- und Dispositionssysteme in der Industrie, Wiesbaden, 12. A., 2000
Mertens, Peter/Griese, Joachim : Integrierte Informationsverarbeitung Bd. 2. Planungs- und Kontrollsysteme in der Industrie, Wiesbaden, 8. A., 2000
Meyer-Wegener, Klaus : Multimedia-Datenbanken, Stuttgart 1991
Oehler, Karsten : OLAP. Grundlagen, Modellierung und betriebswirschaftliche Lösungen, München, Wien 2000
Riebel, Paul : Einzelkosten- und Deckungsbeitragsrechnung, Wiesbaden, 7. A., 1994
Schmalenbach, Eugen : Pretiale Wirtschaftslenkung, Bd. 2: Pretiale Lenkung des Betriebs, Bremen-Horn 1948
Sinzig, Werner : Datenbank-orientiertes Rechnungswesen. Grundzüge einer EDV gestützten Realisierung der Einzelkosten- und Deckungsbeitragsrechnung, Berlin, Heidelberg, New York et al., 3. A., 1990
Smith, John Miles/Smith, Diane C.P. : Database Abstractions: Aggregation and Generalization, in: ACM Transactions on Database Systems, Jg. 2, H. 2/1977, S. 105 – 133
Wedekind, Hartmut : Eine Methodologie zur Konstruktion des konzeptionellen Schemas, in: Datenbanktechnologie, hrsg. v. Niederreichholz, Joachim, Stuttgart 1979, S. 65 – 79
Wedekind, Hartmut/Ortner, Erich : Systematisches Konstruieren von Datenbankanwendungen, München, Wien 1980
|
